
مقایسه کارتگرافیکهای H100، A100 و RTX 6000 PRO Blackwell برای کاربردهای هوش مصنوعی
انتخاب پردازنده گرافیکی مناسب برای پروژههای هوش مصنوعی، به ویژه در حوزه مدلهای زبانی بزرگ، تصمیمی سرنوشتساز و پیچیده است. هر یک از سه کارت گرافیک مورد بررسی، اگرچه محصولی از انویدیا هستند، اما برای کاربردها و بودجهبندی متفاوتی طراحی شدهاند.
انویدیا A100 به عنوان استاندارد طلایی سابق،H100 به عنوان راهکار غالب مراکز داده در سالهای اخیر و RTX 6000 PRO Blackwell به عنوان تازهواردی با معماری به روز و حافظه بالا، گزینههای پیش روی مهندسان و پژوهشگران هستند.
مشخصات فنی و معماری
برای درک تفاوت عملکرد، ابتدا باید به تفاوتهای بنیادین در معماری و مشخصات فنی این سه محصول نگاه کرد. هر یک از این کارتگرافیکها بر پایه یک معماری خاص طراحی شده و ویژگیهای منحصر به فردی را ارائه میدهد.
۱. کارت گرافیک A100 با معماری آمپر
معماری آمپر انقلابی در محاسبات هوش مصنوعی ایجاد کرد. این کارتگرافیک از نسل سوم هستههای تانسور بهره میبرد و قابلیتهایی مانند تیاف۳۲ و اسپارسیتی را معرفی نمود.

رایجترین نسخه کارت گرافیک A100، مدل ۸۰ گیگابایتی با حافظه نوع اچبیام۲ئی و پهنای باند ۲ ترابایت بر ثانیه است. فرم فاکتور این محصول از نوع اساکسام بوده و برای نصب در مراکز داده تخصصی طراحی شده است. این کارت همچنین از فناوری امآیجی پشتیبانی میکند که به کاربران اجازه میدهد یک کارت گرافیک را به چندین بخش مجزا و ایمن تقسیم نمایند.
۲. کارتگرافیک H100 با معماری هاپر
معماری هاپر پیشرفتی قابل توجه نسبت به نسل قبل است. کارتگرافیک H100 از نسل چهارم هستههای تانسور و نوع داده افپی۸ پشتیبانی میکند که عملاً توان محاسباتی را برای این نوع داده نسبت به ای۱۰۰ دوچندان مینماید.

مدل اساکسام این محصول دارای ۸۰ گیگابایت حافظه نوع اچبیام۳ با پهنای باند ۳.۳۵ ترابایت بر ثانیه است که از ای۱۰۰ سریعتر میباشد. فرم فاکتور این محصول نیز از نوع اساکسام بوده و به سیستمهای خنککننده پیشرفته نیاز دارد. توان محاسباتی هستههای تانسور در دقت افپی۱۶ برای این محصول به ۹۸۹ ترافلاپس میرسد که رقمی بسیار چشمگیر است.
۳. انویدیا RTX 6000 PRO Blackwell با معماری بلکول
جدیدترین محصول این خانواده یعنی کارت گرافیک RTX 6000 PRO Blackwell بر پایه معماری بلکول ساخته شده است. تفاوت کلیدی این محصول در نوع حافظه آن است. بر خلاف دو مدل قبلی که از حافظه اچبیام استفاده میکردند، آرتیایکس ۶۰۰۰ پرو از ۹۶ گیگابایت حافظه نوع جیدیدیآر۷ با پهنای باند ۱.۷۹۲ ترابایت بر ثانیه بهره میبرد.

فرم فاکتور این محصول از نوع پیسیآیاکسپرس است که امکان نصب آن را در ایستگاههای کاری معمولی و سیستم های هوش مصنوعی معمولی را فراهم میکند. این محصول از نسل پنجم هستههای تانسور و نوع داده افپی۴ پشتیبانی میکند که پیشرفتهترین فناوری روز برای شتابدهی به استنتاج مدلهای عظیم محسوب میشود. توان محاسباتی هستههای تانسور در دقت افپی۱۶ برای این محصول حدود ۱۲۶ ترافلاپس است که در مقایسه با اچ۱۰۰ پایینتر به نظر میرسد، اما این کاهش توان با بهرهوری انرژی بالاتر و حافظه بیشتر جبران شده است.
تحلیل مقایسهای مشخصات کلیدی
از نظر معماری، کارت گرافیک A100 متعلق به نسل آمپر، کارتگرافیک H100 متعلق به نسل هاپر و کارت گرافیک RTX 6000 PRO Blackwell متعلق به جدیدترین نسل یعنی بلکول است. هر نسل جدید بهبودهای قابل توجهی در بهرهوری انرژی و توان محاسباتی به همراه داشته است.
از نظر مقدار حافظه، کارت گرافیک A100 و کارتگرافیک H100 هر دو ۸۰ گیگابایت حافظه در اختیار کاربر قرار میدهند، در حالی که کارت گرافیک RTX 6000 PRO Blackwell با ۹۶ گیگابایت حافظه، برتری محسوسی در این زمینه دارد. این ۱۶ گیگابایت اضافی میتواند تفاوت زیادی در اجرای مدلهای بسیار بزرگ ایجاد کند.
از نظر نوع حافظه، کارت گرافیک A100 از نوع اچبیام۲ئی، کارتگرافیک H100 از نوع اچبیام۳ و کارت گرافیک RTX 6000 PRO Blackwell از نوع جیدیدیآر۷ استفاده میکند. حافظه اچبیام پهنای باند بالاتری دارد اما گرانتر است، در حالی که جیدیدیآر۷ اگرچه پهنای باند کمتری ارائه میدهد، اما مقرون به صرفهتر و در دسترستر است.
از نظر پهنای باند حافظه، کارت گرافیک A100 با ۲ ترابایت بر ثانیه، اچ۱۰۰ با ۳.۳۵ ترابایت بر ثانیه و کارت گرافیک RTX 6000 PRO Blackwell با ۱.۷۹۲ ترابایت بر ثانیه عمل میکند. اچ۱۰۰ در این شاخص به وضوح برتر است و برای بارهای کاری حساس به پهنای باند مانند آموزش مدلهای بزرگ، بهترین انتخاب محسوب میشود.
از نظر قیمت تقریبی، کارتگرافیک H100 گرانترین گزینه است و قیمت آن در بازار آزاد به چند ده هزار دلار میرسد. کارت گرافیک A100 قیمت متوسطی دارد و در بازار دست دوم با قیمتهای معقولتری یافت میشود. کارت گرافیک RTX 6000 PRO Blackwell از نظر قیمت خرید، گزینهای بین این دو محسوب میشود و نسبت به کارتگرافیک H100 مقرون به صرفهتر است.
تحلیل عملکرد برای هوش مصنوعی
عملکرد این کارتها بسته به نوع بار کاری، یعنی آموزش یا استنتاج و همچنین اندازه مدل، تفاوت چشمگیری دارد.
۱. عملکرد در مرحله آموزش مدل
در حوزه آموزش مدلهای بزرگ، همواره پهنای باند حافظه و توان محاسباتی خام حرف اول را میزند. کارتگرافیک H100 در این بخش برتری مطلق دارد. پهنای باند بالای اچبیام۳ و توان محاسباتی عظیم افپی۸ آن باعث میشود آموزش مدلهایی مانند جیپیتی-۳ تا ۴ برابر سریعتر از ای۱۰۰ انجام شود. برای یک تیم تحقیقاتی که قصد آموزش یک مدل بزرگ از ابتدا را دارد، کارتگرافیک H100 میتواند هفتهها زمان را صرفهجویی کند.
ای۱۰۰ اگرچه سرعتی معادل یکچهارم اچ۱۰۰ در برخی بارها دارد، اما به دلیل بلوغ نرمافزاری و هزینه کمتر، گزینهای مقرون به صرفه برای تیمهای متوسط محسوب میشود. طبق بنچمارکهای معتبر، هزینه اجرای یک دوره آموزشی روی ای۱۰۰ تقریباً نصف اچ۱۰۰ تمام میشود، چراکه اچ۱۰۰ برای مدلهای کوچک به طور کامل اشباع نمیگردد.
اما جایگاه کارت گرافیک RTX 6000 PRO Blackwell در این بخش چیست؟ این کارت با داشتن حافظه جیدیدیآر۷، پهنای باند کمتری نسبت به اچ۱۰۰ دارد. همچنین توان محاسباتی افپی۱۶ آن در مقایسه با اچ۱۰۰ بسیار پایینتر است. با این حال، یک مزیت بزرگ دارد و آن ۹۶ گیگابایت حافظه است. معماری بلکول در این کارت به گونهای طراحی شده که برای استنتاج بهینه است، نه آموزش حجیم. برای آموزش مدلهای بسیار بزرگ، اچ۱۰۰ همچنان پادشاه بلامنازع باقی میماند.
۲.عملکرد در مرحله استنتاج
بخش جذاب ماجرا به استنتاج مربوط میشود، جایی که آرتیایکس ۶۰۰۰ پرو میتواند بدرخشد. بزرگترین چالش در استنتاج مدلهای زبانی بزرگ، ظرفیت حافظه است. برای اجرای یک مدل ۷۰ میلیارد پارامتری در دقت افپی۸، تقریباً به ۷۰ گیگابایت حافظه نیاز خواهد بود.
انویدیا ای۱۰۰ و اچ۱۰۰ هر دو ۸۰ گیگابایت حافظه دارند. این مقدار برای اجرای نسخه افپی۸ مدل ۷۰ میلیاردی کافی است، اما فضای بسیار کمی برای حافظه میانی باقی میگذارد. این موضوع سرعت را در توالیهای طولانی کاهش میدهد و امکان استفاده از سایز بچ بزرگ را محدود میکند.
در سوی دیگر، انویدیا آرتیایکس ۶۰۰۰ پرو با ۹۶ گیگابایت حافظه، فضای تنفس بیشتری دارد. این یعنی میتواند همین مدل ۷۰ میلیاردی را با سایز بچ بزرگتر و سرعت بالاتر، بدون نیاز به دو کارت گرافیک و ارتباطات پرسرعت بین آنها اجرا کند. این ویژگی برای استقرار مدل در محیط تولیدی یک مزیت رقابتی بزرگ محسوب میشود.
بنچمارکهای مستقل نشان میدهند که این کارت در دقت افپی۸ عملکرد بسیار خوبی دارد و در برخی تستها به ۸,۴۰۰ توکن در ثانیه روی مدل ۳۰ میلیاردی دست یافته است. این رقم تقریباً برابر با عملکرد چهار کارت آرتیایکس ۴۰۹۰ است. اگرچه اچ۱۰۰ در حالت تئوری توان محاسباتی افپی۸ بالاتری دارد، اما آرتیایکس ۶۰۰۰ پرو با ارائه حافظه بیشتر، امکان اجرای روانتر مدلهای حجیم را با هزینه سختافزاری کمتر فراهم میکند.
علاوه بر این، پشتیبانی از نوع داده افپی۴ در معماری بلکول، یک برگ برنده بزرگ است. استفاده از افپی۴ به طور تئوری توان خروجی را نسبت به افپی۸ دو برابر میکند. این قابلیت، آرتیایکس ۶۰۰۰ پرو را به گزینهای ایدهآل برای اجرای مدلهای بسیار بزرگ در آینده تبدیل میکند، کاری که از اچ۱۰۰ یا ای۱۰۰ برنمیآید.
تحلیل هزینه و صرفه اقتصادی
در نگاه اول، قیمت خرید اچ۱۰۰ بسیار بالا است و بسیاری از تیمها توانایی تهیه آن را ندارند. اما در محاسبات ابری یا کرایهای، قضیه متفاوت است. نرخ کرایه ساعتی اچ۱۰۰ بالاست و حدود ۲ دلار به ازای هر ساعت برای مدل پیسیآیاکسپرس برآورد میشود.
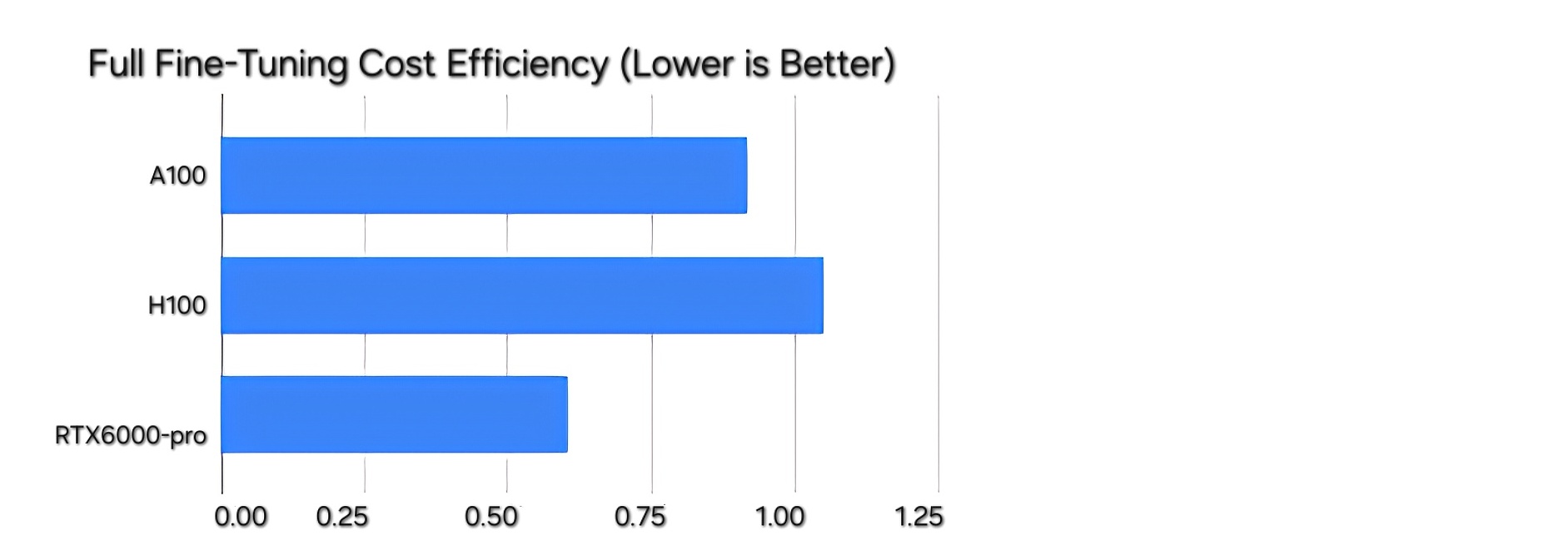
در مقابل، آرتیایکس ۶۰۰۰ پرو به دلیل ماهیت ورکاستیشن بودن و عدم نیاز به زیرساخت خنککننده گرانقیمت مرکز داده، کرایه ساعتی بسیار کمتری دارد. این نرخ به حدود ۰.۷ دلار به ازای هر ساعت میرسد. برای اجرای یک ایپیآی استنتاج، استفاده از آرتیایکس ۶۰۰۰ پرو میتواند هزینه به ازای هر یک میلیون توکن را تا یکسوم اچ۱۰۰ کاهش دهد.
برای مدلهای ۳۰ میلیاردی، هزینه استنتاج با آرتیایکس ۶۰۰۰ پرو حدود ۰.۰۲ دلار به ازای هر یک میلیون توکن تخمین زده میشود. این رقم بسیار رقابتی است و به کسبوکارهای کوچک و متوسط اجازه میدهد بدون صرف هزینههای سرسامآور، مدلهای هوش مصنوعی خود را به صورت زنده ارائه دهند.
نتیجهگیری
کدام یک برای هوش مصنوعی بهتر است؟
پاسخ به این سؤال کاملاً به نیاز خاص شما بستگی دارد و هیچ پاسخ یکسانی برای همه وجود ندارد.
اگر شما در حال آموزش یک مدل زبانی بزرگ از صفر هستید یا به حداکثر توان محاسباتی برای کاهش زمان آموزش نیاز دارید، انویدیا اچ۱۰۰ بدون شک بهترین انتخاب است. هیچ کارت دیگری در این رده قیمتی توان عملیاتی افپی۸ و پهنای باند معادل اچ۱۰۰ را برای محیطهای صنعتی و تحقیقاتی بزرگ ارائه نمیدهد. این کارت برای شرکتهای بزرگ و مراکز تحقیقاتی پیشرفته طراحی شده است.
اگر هدف شما اجرا و استقرار مدل در محیط تولیدی به صورت مقرون به صرفه است، انویدیا آرتیایکس ۶۰۰۰ پرو بلکول انتخاب هوشمندانهتری محسوب میشود. حافظه ۹۶ گیگابایتی آن بستری ایدهآل برای اجرای مدلهای تا ۷۰ میلیارد پارامتر با دقت مناسب فراهم میکند. هزینه عملیاتی پایینتر و پشتیبانی از فناوری جدید افپی۴، آن را به سرمایهای مناسب برای چند سال آینده تبدیل میکند. این کارت گزینهای عالی برای استارتاپها و تیمهایی است که میخواهند مدل خود را با بودجه معقول به صورت زنده اجرا کنند.
اگر بودجه محدودی دارید و به دنبال یک گزینه متعادل برای آموزش و استنتاج مدلهای نسبتاً بزرگ هستید، انویدیا ای۱۰۰ هنوز هم انتخاب قابل قبولی است. این کارت دیگر گزینهای برای پیشرفتهترین پروژهها نیست، اما با توجه به قیمت دست دوم مناسب و پایداری بالای نرمافزار، همچنان در بسیاری از مراکز داده به عنوان یک اسب کار قابل اعتماد فعالیت میکند.
در یک جمله خلاصه:
برای آموزش، اچ۱۰۰ برنده بیرقابت است. برای استنتاج با حجم بالا و بودجه بهینه، آرتیایکس ۶۰۰۰ پرو بلکول گزینهای بهتر و آیندهنگرانهتر به شمار میرود. انتخاب نهایی به بودجه، نوع پروژه و اولویتهای شما بستگی دارد.
دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.